電商搜索系統精講系列三步曲之二 計算機數據服務的基石作用
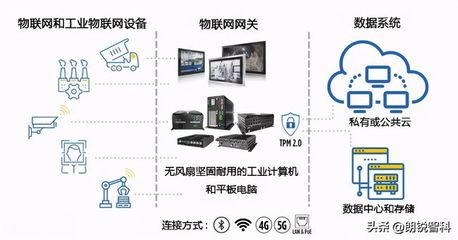
在電商搜索系統的宏大架構中,如果說第一步曲“用戶意圖理解”是系統的“大腦”和“指揮官”,那么第二步曲——計算機數據服務——無疑構成了整個系統的“血液”和“循環系統”。它負責存儲、處理、組織和提供支撐每一次精準搜索所需的海量、多維、實時變化的數據。本篇章將深入剖析數據服務在電商搜索中的核心地位、關鍵技術架構與面臨的挑戰。
一、 數據服務的核心地位:從數據孤島到智慧引擎
電商平臺的數據是極其龐雜的,主要包括:
- 商品數據:標題、描述、屬性(品牌、型號、顏色、尺寸等)、SKU信息、價格、庫存、圖片/視頻等。
- 用戶與行為數據:用戶畫像( demographics、興趣偏好)、搜索歷史、瀏覽軌跡、點擊、加購、收藏、購買、評價等。
- 上下文與環境數據:時間(季節、節假日)、地理位置、設備類型、網絡環境、當前熱門趨勢等。
- 知識圖譜數據:商品間的關聯關系(互補品、替代品)、品類層級、品牌系列等結構化知識。
數據服務的核心任務,就是將這些分散、異構的數據源進行高效的采集、清洗、整合、建模與存儲,構建一個統一、可靠、可擴展的數據底座,為上層搜索的召回、排序、個性化推薦等核心算法提供即時、高質量的數據“燃料”。
二、 關鍵技術架構:構建高效的數據流水線
一個成熟的電商搜索數據服務體系通常采用分層架構:
1. 數據采集與接入層
- 實時流處理:通過Kafka、Flink等框架,毫秒級捕獲用戶行為日志(如點擊、搜索詞變更),用于實時排序模型更新和趨勢感知。
- 批量處理:定期(如每日)從業務數據庫(如商品庫、訂單庫)同步全量或增量數據,用于基礎數據建設和模型全量訓練。
2. 數據存儲與計算層
- 離線數據倉庫:基于Hive、MaxCompute等構建,存儲歷史全量數據,支持復雜的ETL(提取、轉換、加載)和批量分析,用于訓練離線排序模型、構建用戶長期興趣畫像。
- 實時數倉/OLAP引擎:使用ClickHouse、Doris或HBase等,支持對近實時數據的快速多維查詢,滿足實時監控、即席分析和特征快速提取的需求。
- 特征存儲:專門的系統(如Redis、Cassandra或專用特征平臺)存儲為模型預計算好的特征向量(如商品 Embedding、用戶 Embedding),供在線搜索服務極低延遲讀取。
3. 數據建模與服務層
- 特征工程平臺:將原始數據轉化為機器可理解、對預測目標有效的特征,包括統計特征、交叉特征、序列特征、Embedding特征等。
- 向量化與Embedding服務:利用深度學習模型(如BERT、Graph Neural Networks)將商品、用戶、查詢詞映射到同一向量空間,是語義匹配和深度召回的關鍵。
- 在線數據服務:通過高性能RPC或API接口(如gRPC),以極低的延遲(通常要求毫秒級)向搜索排序模塊提供所需的各種特征和向量數據。
4. 數據質量與治理
- 貫穿始終的數據監控、血緣追蹤、一致性校驗和故障恢復機制,確保數據的準確性、及時性和完整性,避免“垃圾進,垃圾出”。
三、 核心挑戰與演進方向
- 規模與性能的平衡:面對百億級商品、數億用戶和每秒數十萬次的查詢,如何在存儲海量數據的保證特征讀取的毫秒級延遲是永恒挑戰。解決方案包括數據分層存儲、智能緩存、計算下推等。
- 數據實時性:電商環境瞬息萬變,價格調整、庫存變動、熱點事件要求數據服務能近實時(秒級甚至毫秒級)更新并生效。流批一體架構成為趨勢。
- 特征管理復雜性:成千上萬的特征需要統一的版本管理、線上/線下一致性保障和高效的生命周期管理。特征平臺(Feature Store)應運而生,成為現代數據架構的標準組件。
- 多模態數據融合:商品信息不再局限于文本,圖片、視頻、3D模型、直播流等富媒體數據日益重要。數據服務需要具備處理和理解多模態信息的能力,生成統一的商品表征。
- 成本與效率:海量數據存儲與計算消耗巨大資源。通過數據壓縮、冷熱數據分離、彈性計算資源調度等方式優化成本,是數據服務團隊的核心職責之一。
###
計算機數據服務是電商搜索系統從“能搜”到“搜得準、搜得智能”的幕后功臣。它不再是簡單的數據存儲和搬運,而是演變為一個集實時處理、智能建模、高效服務于一體的大腦中樞。一個健壯、靈活、智能的數據服務體系,是上層搜索算法持續迭代和創新的堅實基石。在下一篇中,我們將進入三步曲的最終章——搜索排序與策略,探討如何利用數據服務提供的“彈藥”,在毫秒間完成從海量候選商品中篩選出最優結果的智慧決策過程。
如若轉載,請注明出處:http://www.eqguuzzrr.cn/product/45.html
更新時間:2026-01-06 06:52:39